Neural Networks at a Glance
This article provides a concise yet comprehensive overview of neural networks, the cornerstone of modern artificial intelligence (AI). It covers their structure, functionality, and applications, tailored for system design interviews and engineers seeking a foundational understanding of AI systems.
What is a Neural Network?
A neural network is a computational model inspired by the human brain, designed to learn patterns from data. It consists of interconnected nodes (or neurons) organized in layers that process input data to produce meaningful outputs, such as predictions, classifications, or generated content.
Neural networks are the backbone of many AI applications, from image recognition to natural language processing (NLP).
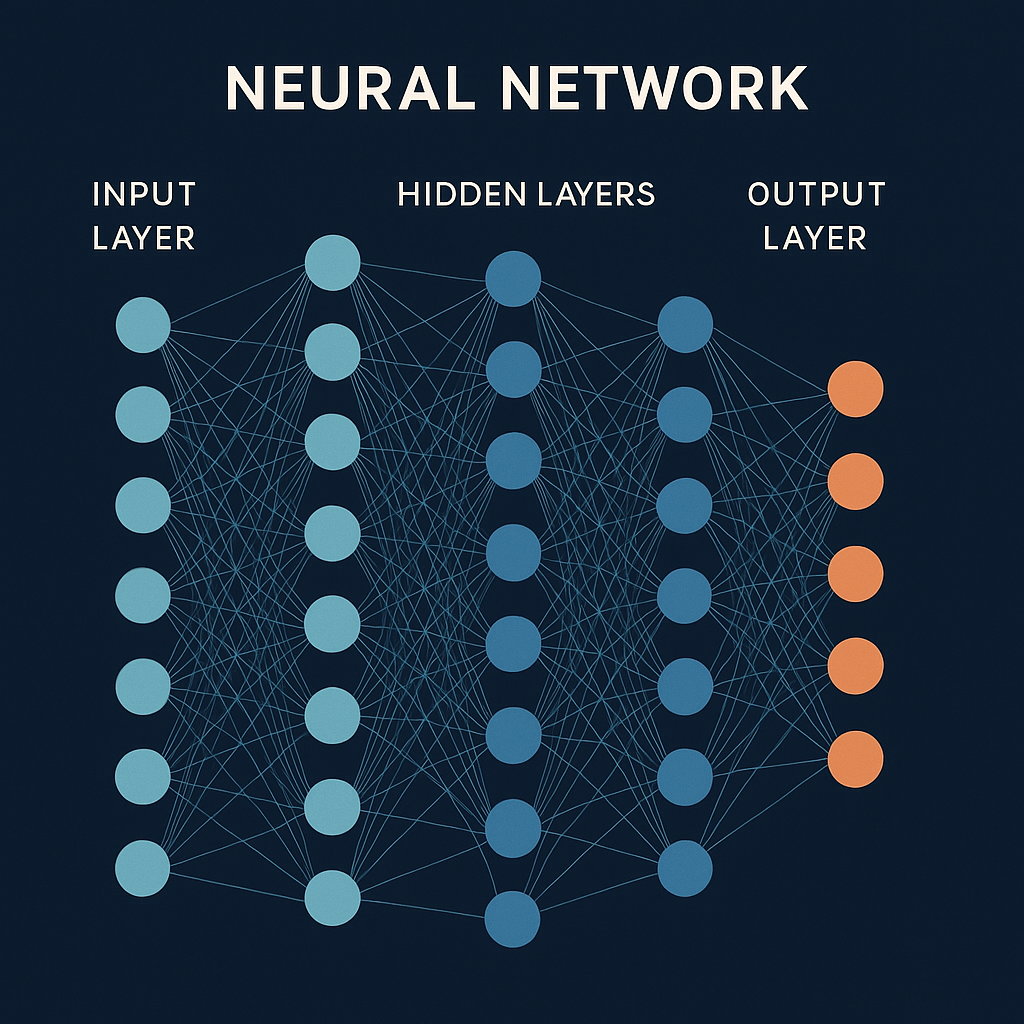
Structure of a Neural Network
Neural networks are composed of three main types of layers:
Input Layer:
- Receives raw data (e.g., pixel values of an image, word embeddings for text).
- Each node represents a feature of the input (e.g., a pixel intensity or a word’s numerical representation).
Hidden Layers:
- Process the input data through weighted connections and transformations.
- Each layer extracts increasingly complex features (e.g., edges in images, phrases in text).
- Deep neural networks have multiple hidden layers, enabling complex pattern recognition.
Output Layer:
- Produces the final result, such as a classification (e.g., “cat” vs. “dog”), a probability, or generated content (e.g., a sentence).
- The output format depends on the task (e.g., single value for regression, probabilities for classification).
Key Components
- Nodes (Neurons): Perform computations by combining inputs with weights, adding a bias, and applying an activation function.
- Weights: Adjustable parameters that determine the importance of each input.
- Bias: A constant added to shift the output, improving model flexibility.
- Activation Function: Introduces non-linearity, enabling the network to learn complex patterns. Common functions include:
- ReLU (Rectified Linear Unit): ( f(x) = \max(0, x) ), widely used for simplicity.
- Sigmoid: ( f(x) = \frac{1}{1 + e^{-x}} ), outputs values between 0 and 1 for probabilities.
- Tanh: Similar to sigmoid but outputs between -1 and 1.
- Softmax: Converts raw scores into probabilities for multi-class classification.
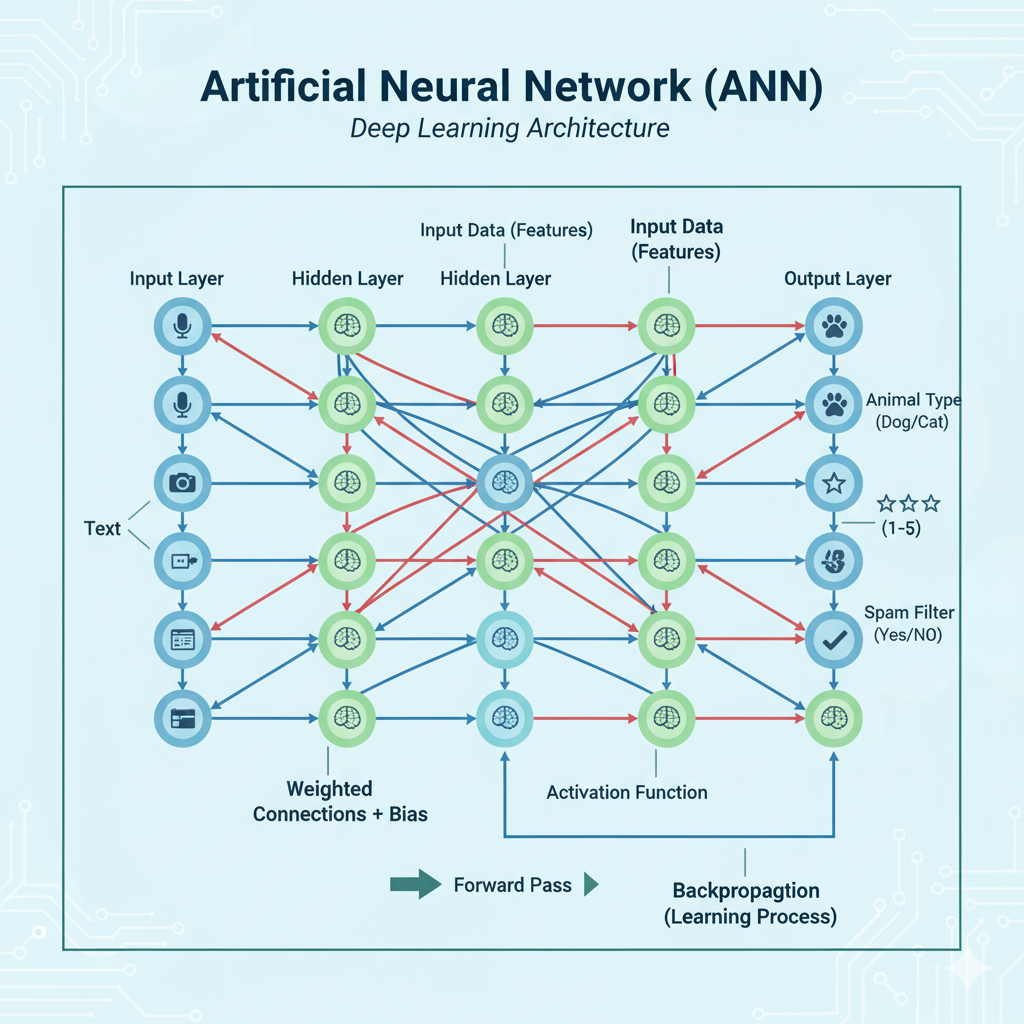
How Neural Networks Work
Neural networks operate in two phases: training and inference.
1. Training Phase
Goal: Adjust weights and biases to minimize prediction errors.
Process:
- Forward Propagation:
- Input data passes through the layers.
- Each node computes: ( output = activation(\sum(weight \cdot input) + bias) ).
- The output layer produces a prediction.
- Loss Calculation:
- A loss function measures the difference between predicted and actual outputs (e.g., mean squared error for regression, cross-entropy for classification).
- Backpropagation:
- Computes gradients of the loss with respect to weights and biases using the chain rule.
- Gradients indicate how much each parameter contributes to the error.
- Optimization:
- An algorithm like gradient descent updates weights and biases to minimize the loss.
- Variants like Adam or RMSprop optimize convergence speed and stability.
- Iteration:
- Repeat for many epochs (passes over the dataset) until the model converges.
- Forward Propagation:
Example: In a digit recognition network, the model learns to map pixel values to digits (0–9) by adjusting weights to reduce errors in predictions.
2. Inference Phase
- Goal: Use the trained model to make predictions on new data.
- Process:
- Input data passes through the network (forward propagation only).
- The output layer produces the final result (e.g., “This is a 7” for a handwritten digit).
- Example: A trained model takes an image of a digit and outputs a probability distribution over possible digits.
Types of Neural Networks
Different neural network architectures are designed for specific tasks:
Feedforward Neural Networks (FNNs):
- Simplest type, with data flowing in one direction (input → hidden → output).
- Used for basic classification or regression tasks (e.g., predicting house prices).
Convolutional Neural Networks (CNNs):
- Specialized for image and spatial data.
- Use convolutional layers to detect features (e.g., edges, textures) and pooling layers to reduce dimensionality.
- Applications: Image recognition, facial detection.
Recurrent Neural Networks (RNNs):
- Designed for sequential data (e.g., time series, text).
- Use loops to maintain “memory” of previous inputs.
- Variants like LSTM (Long Short-Term Memory) and GRU (Gated Recurrent Unit) handle long-term dependencies.
- Applications: Speech recognition, language modeling.
Transformers:
- Advanced architecture for NLP and beyond, using attention mechanisms to weigh the importance of different inputs.
- Highly parallelizable, unlike RNNs, making them efficient for large datasets.
- Applications: Language models (e.g., BERT, GPT), machine translation.
Generative Adversarial Networks (GANs):
- Consist of two networks: a generator (creates data) and a discriminator (evaluates data).
- Used for generating realistic images, audio, or text.
- Applications: Deepfakes, image synthesis.
Why Neural Networks are Powerful
- Non-Linearity: Activation functions allow neural networks to model complex, non-linear relationships.
- Scalability: Deep networks with many layers can learn hierarchical features (e.g., edges → shapes → objects).
- Adaptability: Can be tailored to various tasks (e.g., vision, language, audio).
- Data-Driven: Learn directly from data, reducing the need for manual feature engineering.
Challenges of Neural Networks
- Computational Cost: Training requires significant compute power (e.g., GPUs/TPUs) and large datasets.
- Overfitting: Models may memorize training data instead of generalizing, mitigated by techniques like dropout or regularization.
- Interpretability: Neural networks are often “black boxes,” making it hard to understand their decisions.
- Hyperparameter Tuning: Choosing the right architecture, learning rate, or layer size requires experimentation.
Real-World Context
- Interview Relevance: System design interviews may ask about neural network architecture for tasks like recommendation systems or chatbots. Explain layer types, training, and hardware needs.
- Practical Use: Neural networks power applications like autonomous vehicles (CNNs for vision), virtual assistants (Transformers for NLP), and medical diagnostics (CNNs for imaging).
- Modern Trends:
- Efficient Models: Techniques like pruning and quantization reduce model size for edge devices.
- Self-Supervised Learning: Models like BERT learn from unlabeled data, reducing data annotation costs.
- AI Ethics: Addressing bias and fairness in neural network outputs is critical.
Further Reading
- Deep Learning by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
- Neural Networks and Deep Learning by Michael Nielsen (free online)
- Google’s Transformer paper: “Attention is All You Need” (Vaswani et al., 2017)
- Blogs from NVIDIA, DeepMind, and Hugging Face on neural network advancements