Distributed Systems: CAP & Consensus
Distributed systems power modern scalable, resilient applications. But they introduce fundamental challenges: how to remain consistent, available, and fault-tolerant despite failures and network partitions. Two cornerstone ideas help us reason about these systems: the CAP theorem and consensus algorithms like Paxos and Raft.
1. The CAP Theorem
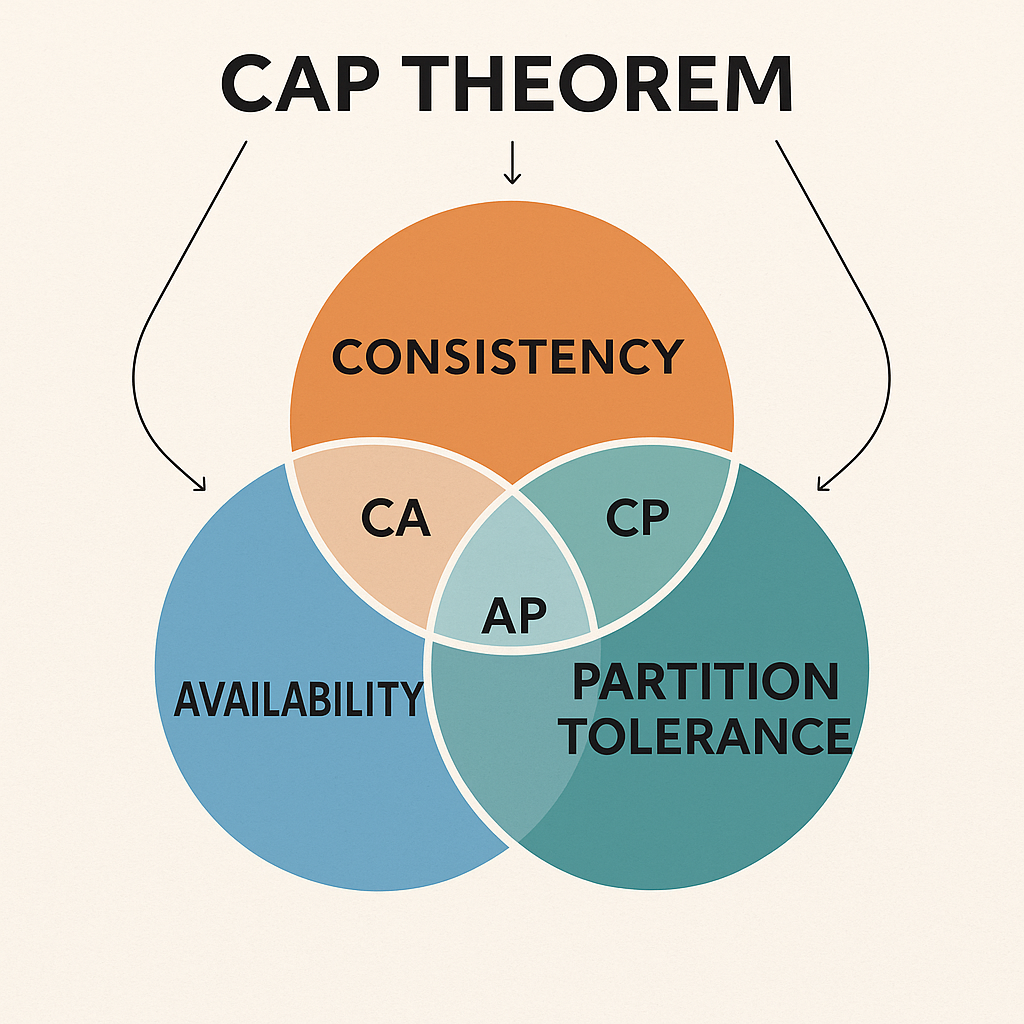
Definition: In any distributed system, you can only guarantee two of the following three properties at the same time:
- Consistency (C) – All nodes see the same data at the same time.
- Availability (A) – Every request gets a response, even if some nodes fail.
- Partition Tolerance (P) – The system continues to operate despite network failures.
Trade-offs
- CP (Consistency + Partition tolerance): Prioritize correctness, may sacrifice availability. Example: ZooKeeper.
- AP (Availability + Partition tolerance): Prioritize serving requests, may allow stale reads. Example: DynamoDB, Cassandra.
- CA: Rarely practical because network partitions always exist.
👉 Interview Tip: Be ready to reason about trade-offs: “For a payment system I’d choose CP, for a social feed AP is acceptable.”
2. Consensus in Distributed Systems
Distributed systems often need nodes to agree on a single value: who is the leader? what’s the next transaction?. This agreement process is called consensus.
Two famous protocols are Paxos (theoretically foundational but complex) and Raft (practically adopted for being easier to understand).
Paxos (Leslie Lamport, 1990)
Goal: Ensure a cluster of nodes agree on one value, even if some nodes or messages fail.
Roles:
- Proposers → suggest values.
- Acceptors → vote and decide.
- Learners → learn the chosen value.
Phases (simplified)
- Prepare Phase: Proposer sends a numbered proposal. Acceptors promise to ignore lower numbers.
- Accept Phase: If majority promised, proposer asks acceptors to accept its value.
- Learning Phase: Once majority accepts, the value is chosen and shared.
Why it matters
- Tolerates node crashes and message loss.
- Guarantees safety (no conflicting decisions).
- But is difficult to implement correctly.
👉 Interview Tip: Mention majority quorum and two-phase agreement.
Raft (2014, Ongaro & Ousterhout)
Raft was designed to be easier to understand while solving the same consensus problem.
Roles:
- Leader – central authority for client requests.
- Followers – passive, replicate leader’s log.
- Candidates – temporary role during leader elections.
Phases
- Leader Election: Followers become candidates if they don’t hear from a leader. Majority votes elects a leader.
- Log Replication: Leader appends commands and replicates to followers. Once a majority acknowledge, the entry is committed.
- Safety via Terms: Each election has a term number; outdated leaders cannot override newer ones.
Why it matters
- Simpler mental model than Paxos.
- Widely used in systems like etcd (Kubernetes), Consul, Nomad.
- Provides both consensus and log replication.
👉 Interview Tip: Highlight leader-driven replication and simplicity over Paxos.
Paxos vs Raft (Comparison)
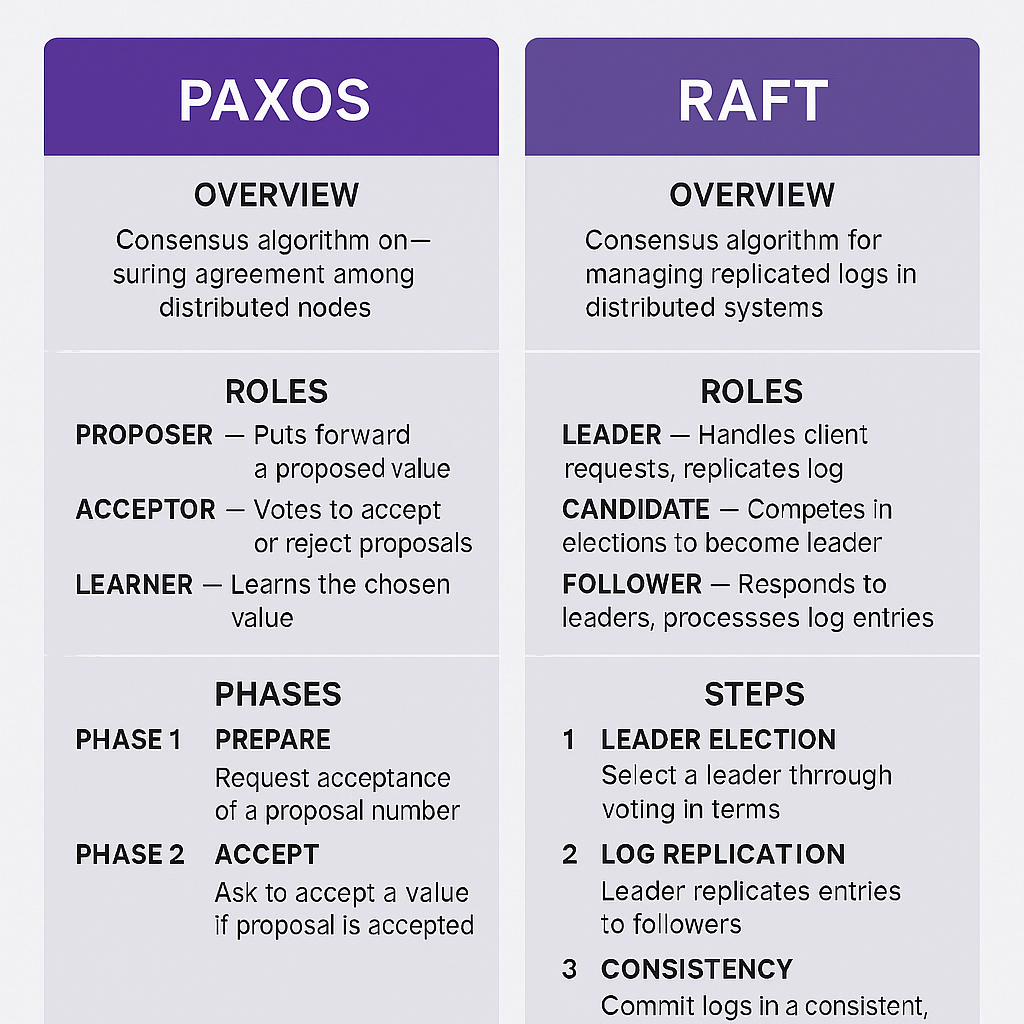
| Feature | Paxos | Raft |
|---|---|---|
| Understandability | Harder, academic | Easier, designed for teaching |
| Roles | Proposer, Acceptor, Learner | Leader, Follower, Candidate |
| Decision making | Multiple proposers may race | Single leader coordinates |
| Log Replication | Not explicit in basic Paxos | Built-in, core to protocol |
| Usage in practice | ZooKeeper, Chubby, Spanner | etcd, Consul, Kubernetes control plane |
3. Key Takeaways
- CAP Theorem → you can’t have it all, must reason about trade-offs.
- Consensus → majority agreement ensures safety, but limits availability during partitions.
- Paxos → correct but complex, foundational in theory.
- Raft → leader-based, simpler, widely used in practice.
4. Practice Question
“Design a leader election mechanism for a distributed system that tolerates partitions. Which consensus protocol would you choose and why?”
- For theory-heavy discussion: Paxos (quorum, two-phase).
- For practical engineering: Raft (leader election, log replication, used in Kubernetes).
5. Interview Answer Example
“In a distributed key-value store, I’d use Raft. A leader handles client writes, replicates logs to followers, and commits entries once a majority acknowledge. This ensures consistency and fault tolerance, at the cost of temporary unavailability during partitions.”
Further Reading
- Designing Data-Intensive Applications – Martin Kleppmann
- Paxos Made Simple – Leslie Lamport
- In Search of an Understandable Consensus Algorithm (Raft paper) – Ongaro & Ousterhout
- Etcd & Kubernetes docs (real-world Raft usage)